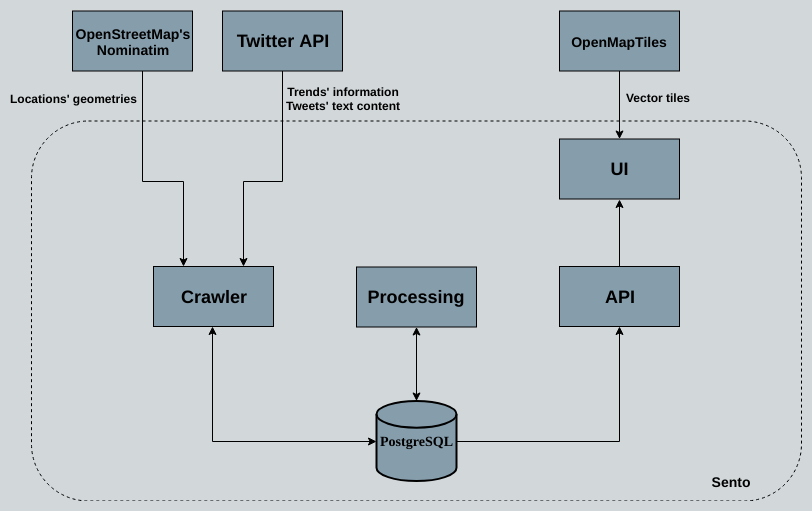
In this post I will introduce you the architecture of Sento. The project consists of the following components:
Crawler
This piece of software communicates with Twitter’s and OpenStreeMap Nominatim’s APIs and does the following tasks:
- Extracts the text content in tweets beloging to the current available trends.
- Extracts metadata information from the trends themselves*, such as:
- How did the trend rank during its lifetime in a certain location.
- In which locations did the trend appear.
- Where did the trend start.
- Extracts the geometry of the locations where trends are available.
Retreived data will be stored in a PostgreSQL database using defined models.
* In order to provide precise metadata it is required that the crawler is running before the trend starts.
Processing
Processes the tweets extracted for each trend and categorises them in three groups: positive, neutral o negative perception towards the trend’s topic.
In order to categorise each text it is necessary apply Natural Language Processing techniques focused on sentiment analysis.
API
Exposes the results obtained in the processing pipeline and the data retrieved in the extraction pipeline through a HTTP API. This API will enable other applications to consume the data produced.
UI
Consumes the data exposed through Sento’s API, enabling analysis to be carried out. In order to being able to render a map, an OpenMapTiles Server self hosted instance will be used to deliver Mapbox Vector Tiles.
The big picture
The following diagram is a big picture containing all the described pieces.